Doctor Droid
Autonomous cloud diagnostics platform that automates incident resolution
Introduction
What is Doctor Droid?
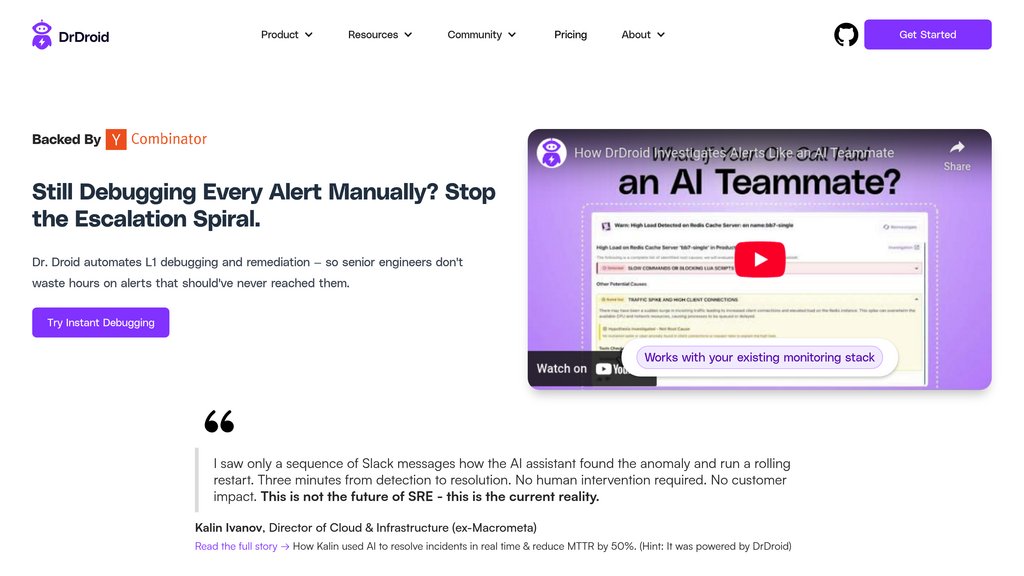
Doctor Droid acts as an intelligent assistant that speeds up incident triage and automates root cause analysis for infrastructure and platform teams. It seamlessly integrates with monitoring, alerting, and deployment systems to examine alerts, logs, metrics, and recent updates, producing dynamic investigation plans and practical insights. By handling routine diagnostics and minimizing alert distractions, it empowers teams to act swiftly and concentrate on high-impact decisions, boosting operational stability without altering existing processes.
Key Features:
• Autonomous Incident Investigation: Independently evaluates alerts and system information to create customized, step-by-step diagnostic strategies based on your environment, runbooks, and historical incidents.
• Deep Integrations: Works with widely-used platforms such as Datadog, Grafana, ArgoCD, Kubernetes, New Relic, and GitHub to collect extensive observability and deployment data.
• Runbook Automation with Playbooks: Allows the design and implementation of automated workflows that execute standard IT operations and incident reactions without manual input.
• Alert Noise Reduction: Applies adaptive thresholds and pattern recognition to eliminate false alerts and cluster connected incidents, enhancing alert clarity and minimizing fatigue.
• Continuous Documentation and RCA Generation: Automatically refreshes incident records and creates root cause analysis summaries to ensure knowledge remains current and simplify post-incident analysis.
• Flexible Deployment and Security: Offers both self-hosted and cloud-based options with robust security protocols, including a default read-only mode and managed execution for state modifications.
Use Cases:
• Incident Response Automation: Automates alert investigation and initial diagnostic steps to lower mean time to acknowledge (MTTA) and mean time to resolve (MTTR).
• Alert Management and Noise Reduction: Enhances alert quality by filtering out irrelevant signals and highlighting urgent issues, enabling teams to prioritize real problems.
• Runbook Execution and Task Automation: Automates everyday operational duties such as service restarts, log clearance, or metric queries to decrease manual efforts.
• Continuous Incident Documentation: Maintains automatic updates of incident reports and root cause analyses, supporting knowledge transfer and proactive prevention.
• Cloud Infrastructure Monitoring: Oversees Kubernetes clusters, deployments, and cloud services with built-in diagnostic capabilities for quicker root cause detection.