LM Arena (Chatbot Arena)
Open-source LLM battle platform: anonymous voting ranks AI models in real-time
Introduction
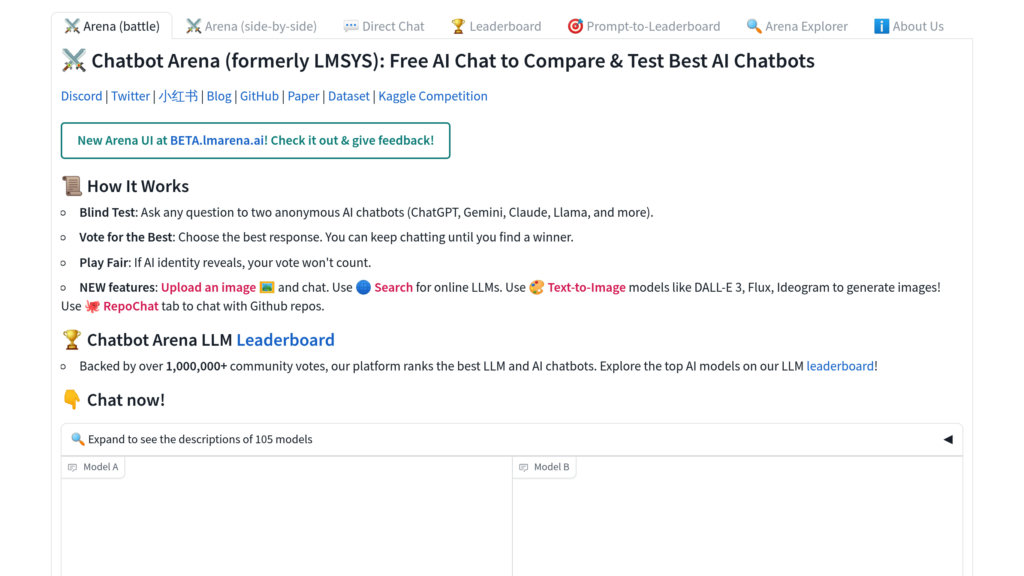
LM Arena, also referred to as Chatbot Arena, is a collaborative, open-source initiative from LMSYS and UC Berkeley SkyLab designed to foster the evolution and comprehension of large language models via transparent, community-powered, real-time assessments. It allows users to anonymously pit multiple LLMs against each other, gathering votes to establish performance rankings using the Elo system. The platform accommodates a diverse array of publicly available models—including open-weight and commercial API-based ones—and constantly refreshes its leaderboard with fresh user input. A core principle is its commitment to open science, with datasets, evaluation tools, and platform code shared publicly on GitHub.
Key Features
Community-Powered Model Battles: Users participate in anonymous, randomized duels between two LLMs, casting votes for the superior response to create robust comparative insights.
Dynamic Elo-Based Rankings: Employs the established Elo rating system to deliver statistically reliable and ever-evolving performance standings.
Fully Open-Source Platform: The entire infrastructure—from user interface and server logic to evaluation workflows and ranking methods—is open for public access and contribution.
Real-Time, Ongoing Assessment: The continuous influx of user prompts and votes enables benchmarking that stays current with model advancements and practical applications.
Inclusion of Public Models: Features models that are open-weight, accessible via public APIs, or offered as services, guaranteeing evaluation transparency and reproducibility.
Commitment to Open Collaboration: Actively promotes wide involvement and openly distributes user preference data and prompts to accelerate collaborative AI research.
Use Cases
Real-World LLM Benchmarking: Researchers and developers can assess and contrast the capabilities of various large language models in scenarios that mimic actual usage.
Informed Model Selection for Applications: Businesses and institutions can leverage the live, community-generated rankings to pinpoint the most effective LLMs for their specific needs.
Advancing Open Science: Academics and AI professionals can utilize the shared datasets and tools to conduct reproducible studies and drive model innovation.
Gathering Feedback for Model Refinement: AI developers can collect anonymized user votes and feedback to fine-tune their systems prior to wider release.