LanceDB
Open-source vector database for petabyte-scale multimodal data storage
Introduction
What is LanceDB?
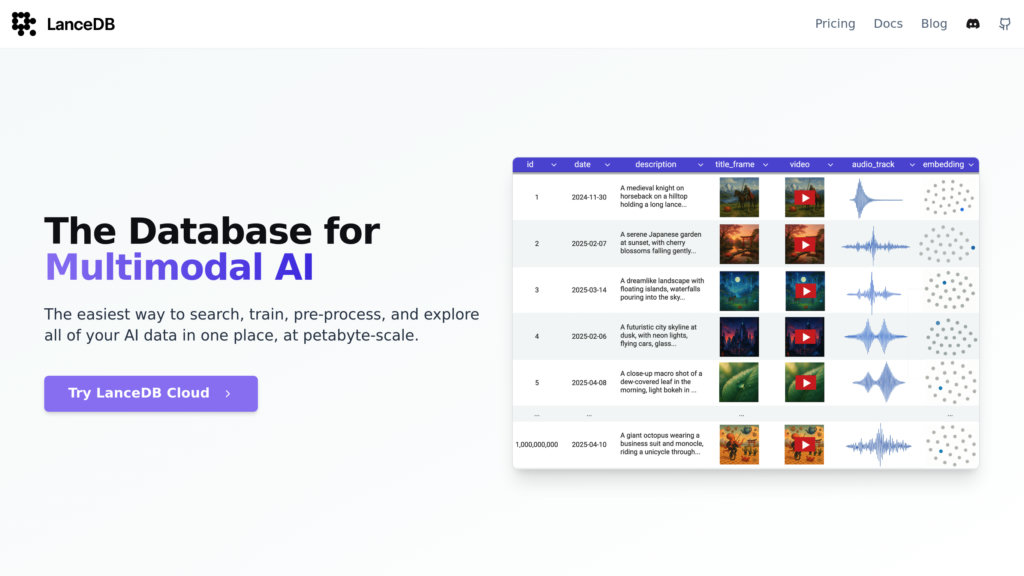
LanceDB is an open-source vector database engineered for top-tier performance, specializing in the storage, retrieval, and management of vector embeddings along with raw multimodal data such as text, images, videos, and 3D point clouds. Its foundation is the custom Lance columnar format, which empowers it to deliver production-ready vector similarity search capabilities without the overhead of server administration. With options for embedded or serverless deployment, built-in data versioning, and smooth compatibility with leading AI and data tools, LanceDB is perfectly suited for AI applications scaling from initial prototypes to massive enterprise systems.
Key Features:
• Large-Scale Vector Search: Execute rapid, low-latency similarity searches across billions of vectors without deploying any server infrastructure.
• Multimodal Data Handling: Effortlessly manage and query vectors in conjunction with their original data types, including text, images, videos, and point clouds.
• Built-in Data Versioning: Automatically track multiple versions of your datasets, simplifying iterative model training and data governance without additional tools.
• Flexible Deployment Models: Choose between embedding the database directly within your application or leveraging a scalable serverless architecture.
• Efficient Columnar Storage: Leverage a high-performance columnar data format for swift access and seamless integration with data science tools via Apache Arrow.
• Broad Ecosystem Compatibility: Enjoy native support for Python and JavaScript/TypeScript, plus integrations with LangChain, LlamaIndex, Pandas, Polars, and DuckDB.
Use Cases:
• Semantic Search Engines: Enable swift and precise similarity searches across extensive document libraries using vector embeddings.
• Recommendation Systems: Store and retrieve user and item vectors to provide highly personalized content and product suggestions.
• Generative AI Data Management: Efficiently handle training datasets and model outputs for text, image, and multimodal AI pipelines.
• Content Moderation: Rapidly identify and filter unsuitable content by searching through vectors that represent key content features.
• AI-Powered Chatbots and Agents: Retrieve contextually relevant information vectors to power coherent and knowledgeable conversational AI systems.