Janus Pro
Open-source multimodal AI for intelligent image understanding and generation
Introduction
What is Janus Pro?
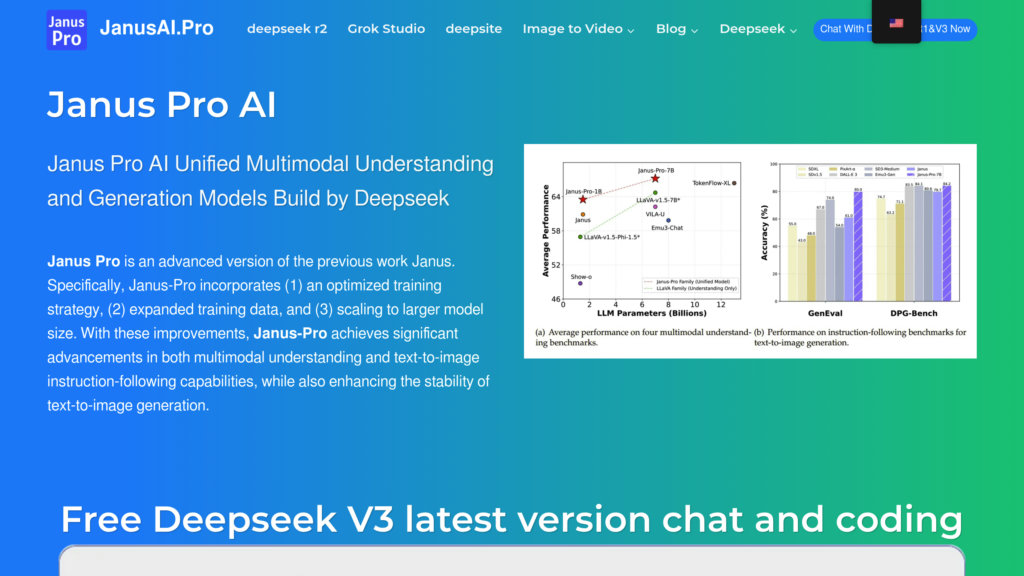
Developed by DeepSeek, Janus Pro represents a breakthrough in multimodal artificial intelligence, seamlessly merging the abilities to understand and generate visual content within one cohesive Transformer-based system. It introduces an innovative decoupled visual encoding mechanism that independently refines the processes for analyzing and creating images, leading to greater adaptability and precision. The model was trained on a massive collection of both authentic and artificially generated data, enabling it to exceed the performance of top-tier models such as DALL-E 3 in text-to-image generation, evidenced by a leading GenEval score of 0.80 compared to 0.67. Offered in 1 billion and 7 billion parameter versions under the permissive MIT license, it permits full commercial utilization and is readily available on platforms including Hugging Face and GitHub. Its efficient architecture and economical scalability make it a perfect choice for developers, research teams, and companies looking for a powerful and versatile AI solution for multimodal tasks.
Key Features
Unified Multimodal Architecture: Utilizes a single Transformer framework with distinct pathways for visual encoding, allowing efficient management of both image analysis and creation.
Superior Performance: Achieves a benchmark GenEval score of 0.80, surpassing prominent models like DALL-E 3 and Stable Diffusion, particularly in accurately following text-based instructions for image generation.
Open-Source and Commercial Friendly: Distributed under the MIT license, granting freedom for use, modification, and commercial application, with complete code and model access on Hugging Face and GitHub.
Optimized Vision Processing: Handles images at a resolution of 384×384 pixels using the advanced SigLIP-L vision encoder alongside MLP adapters for effective feature extraction and seamless task transitioning.
Cost-Effective Scalability: The streamlined 7-billion-parameter design lowers computational requirements and expenses relative to proprietary options, encouraging wider implementation.
Extensive Training and Fine-Tuning: Benefited from a multi-stage training process on a vast blend of real and synthetic datasets, improving model stability, accuracy, and the fusion of multimodal capabilities.
Use Cases
Commercial AI Solutions: Integrate affordable multimodal AI into business operations to boost visual content creation and comprehension.
AI-Powered Image Generation: Produce high-fidelity images from textual descriptions for creative endeavors, design mock-ups, and marketing materials.
Image Understanding and Analysis: Conduct sophisticated image recognition, visual question answering, and object or landmark detection for educational and diagnostic purposes.
Optical Character Recognition (OCR): Efficiently pull text from images to aid in document digitalization, information retrieval, and process automation.
Research and Development: Employ this open, adaptable multimodal model for academic studies and pioneering AI projects.